
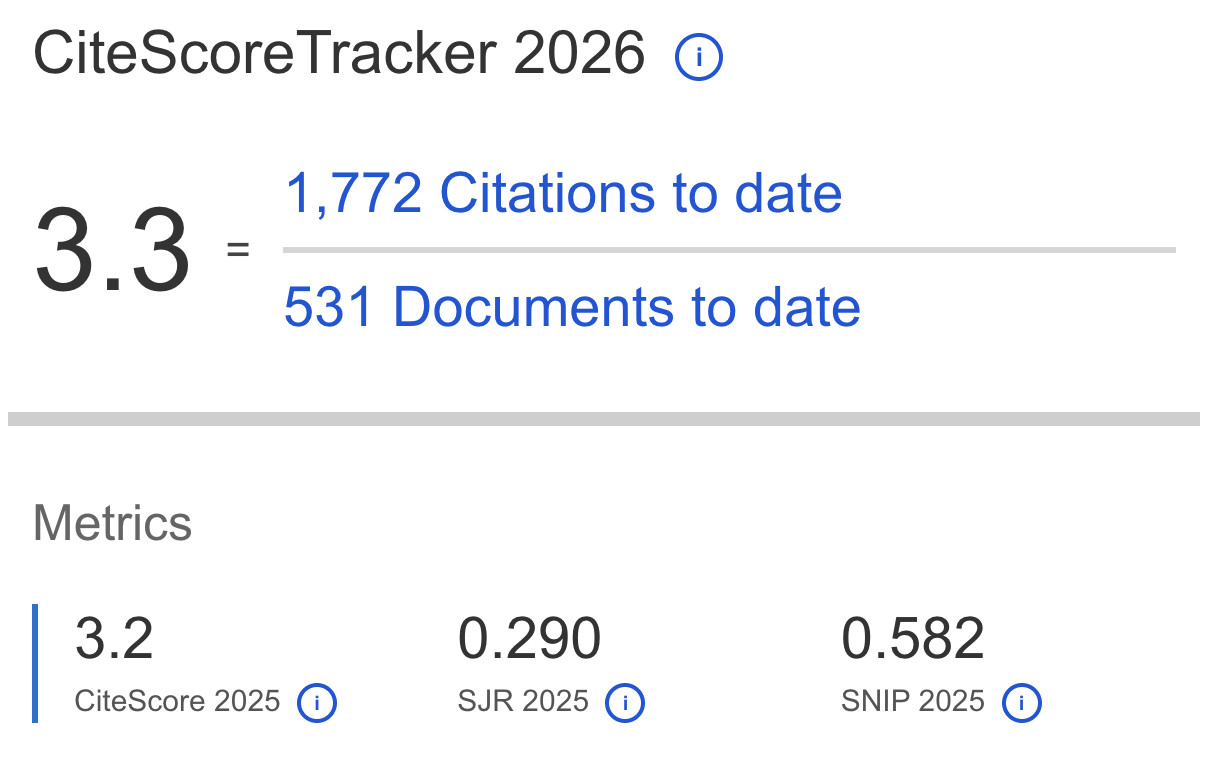
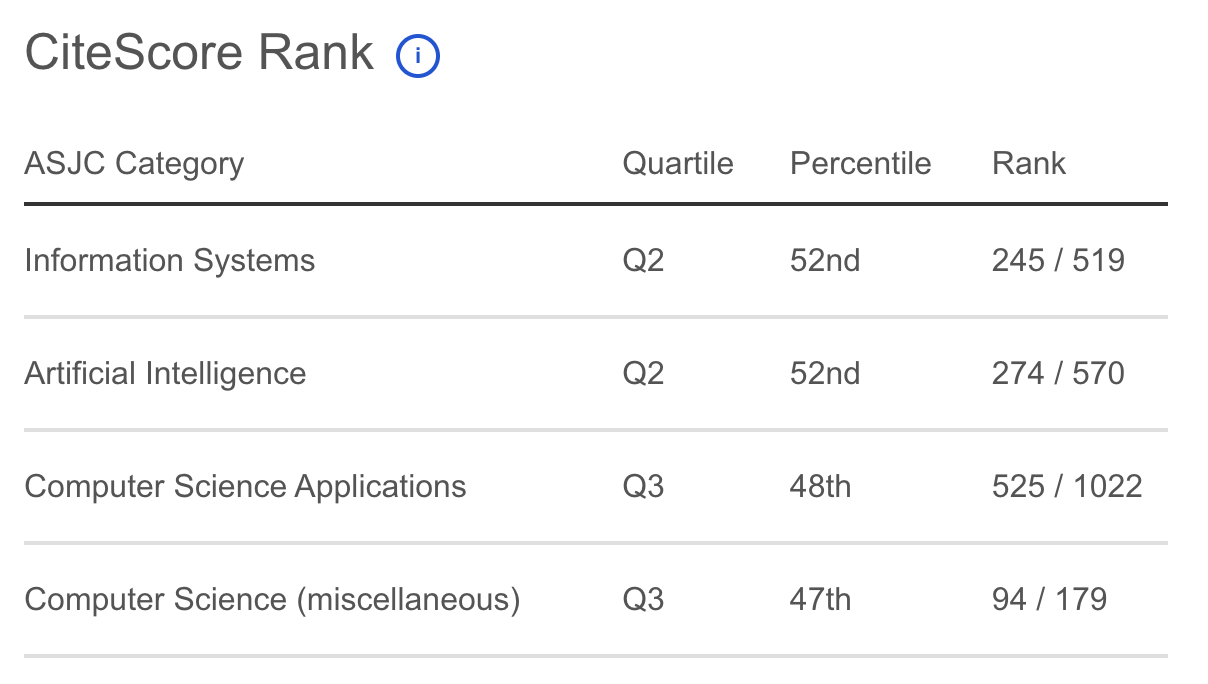
.png)
Implementation of the K-Nearest Neighbor Algorithm for the Classification of Student Thesis Subjects
Abstract
Students who have studied for a considerable amount of time and will complete a lecture process must complete the necessary final steps. One of them is writing a thesis, a requirement for all students who wish to graduate from college. Each student's choice of topic or specialization will be enhanced if it not only corresponds to their interests but also to their skills. K-Nearest Neighbor is one of the classification techniques used. K-Nearest Neighbor (KNN) operates by determining the shortest distance between the data to be evaluated and the K-Nearest (neighbor) from the training data. K-Nearest Neighbor is utilized to classify new objects based on the learning data closest to the new object. Therefore, KNN is ideally suited for classifying data to predict student thesis topics. This research concludes that optimizing the k value using k-fold cross-validation yields an accuracy rate of 79.37% using k-fold cross-validation = 2 and the K-5 value. Based on the K-Nearest Neighbor Algorithm classification results, 45 students are interested in computational theory thesis (RPL) topics, 32 students are interested in artificial intelligence (AI) thesis topics, and 21 students are interested in software development topics.
Article Metrics
Abstract: 724 Viewers PDF: 333 ViewersKeywords
KNN, RPL, Artificial Intelligence
Full Text:
PDF
DOI:
https://doi.org/10.47738/jads.v3i3.66
Citation Analysis:
Refbacks
- There are currently no refbacks.

Journal of Applied Data Sciences
| ISSN | : | 2723-6471 (Online) |
| Publisher | : | Bright Publisher |
| Website | : | http://bright-journal.org/JADS |
| : | taqwa@amikompurwokerto.ac.id (principal contact) | |
| support@bright-journal.org (technical issues) |
 This work is licensed under a Creative Commons Attribution-ShareAlike 4.0
This work is licensed under a Creative Commons Attribution-ShareAlike 4.0